Understanding Transfer Learning for Medical Imaging
Transfer learning (a.k.a. ImageNet pre-training) is a common practice in deep learning where a pre-trained network is fine-tuned on a new dataset/task. This practice is implicitly justified by feature-reuse where features learned from ImageNet are beneficial to other datasets/tasks. This paper [1] evaluates this justification on medical images datasets. The paper concludes that (i) transfer learning does not significantly help performance, (ii) smaller, simpler convolutional architectures perform comparably to standard ImageNet models, and (iii) there are feature-independent, and not feature-reuse, benefits to pre-training, i.e., speed convergence.
The paper highlights three differences between ImageNet and medical images datasets:
- ImageNet images has a global subject while malignant tissues (diseases) manifest as local texture variations in medical images as shown in Fig. 1.
- The number of images in ImageNet is significantly larger than the number of images in any medical images dataset.
- ImageNet has a large number of classes (categories), while medical images datasets have significantly fewer classes. The number of possible diseases in medical images is small; E.g., 5 classes for diabetic retinopathy diagnosis.

These three differences question the idea of feature-reuse. To quantitatively evaluate the feature-reuse justification, the paper uses two medical images datasets: Retina and CheXpert. Tables 1 and 2 report performance on these two datasets, respectively. For quantitative evaluation, both large standard and small convolutional neural networks are utilized. ResNet-50 and Inception-v3 represent large standard networks, while custom-made CBR models represent small convolutional networks.


Tables 1 and 2 show that transfer learning has minimal impact on performance: not helping the smaller CBR architectures at all while providing a marginal gain for ResNet and Inception. Another key observation is that performance of the CBR architectures on ImageNet is not a good indication of success on medical datasets.
The paper then evaluates the same models in a low-data regime. To evaluate performance in this regime, the paper uses only 5000 data points from the Retina dataset. Table 3 presents a quantitative evaluation on the low-data regime. While pre-training boosts ResNet50 significantly (92.2->94.6), this happens because ResNet50 is designed with millions of parameters for large datasets. Accordingly, a randomly initialized ResNet50 is likely to overfit on a 5000 datapoints dataset, while a pre-trained ResNet50 won’t. As shown in Table 3, transfer learning has minimal impact on small models.

Following the previous two evaluations, the paper further investigates the following questions:
- Does transfer learning result in any representational differences compared to training from random initialization? Or are the effects of the initialization lost?
- Does feature reuse take place, and if so, where exactly?
To answer these questions, the paper quantifies the similarity between the networks’ representations. The similarity is quantified using (Singular Vector) Canonical Correlation Analysis, (SV)CCA. Figure 2 shows the similarity score after training two randomly initialized networks (blue) against the similarity score after training a randomly initialized network and a pre-trained network (orange).
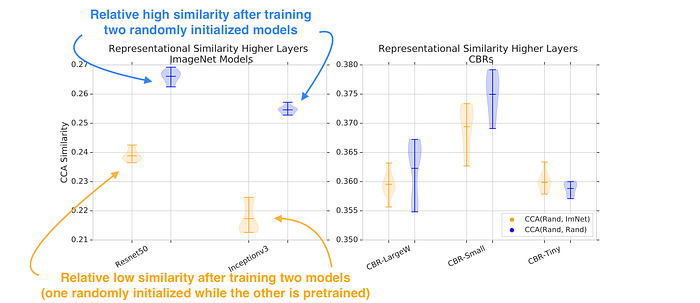
Figure 2 shows a difference between representations, with the similarity of representations between (Rand, ImNet) in orange noticeably lower than representations learned independently from different random initializations (blue). However, for smaller models (CBRs), the functions learned are similar.
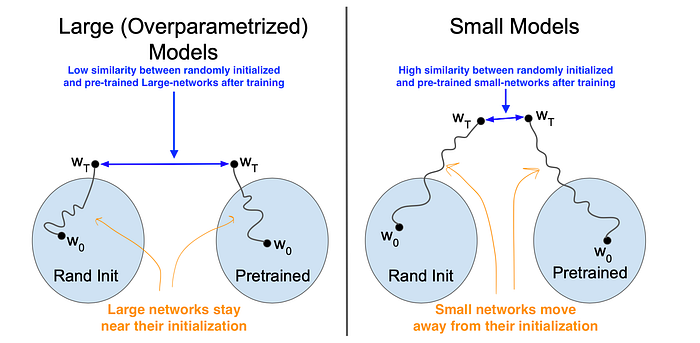
To further emphasize this idea, the authors depict their intuition about large and small models as shown in Fig. 3. Large models move less and, accordingly, there is a low similarity between randomly initialized and pre-trained networks after training. In contrast, small models move far from their initialization and tend to converge to similar representations.
In Fig. 2, the similarity scores were calculated using the penultimate layer in each network — before global average pooling. The paper digs deeper to measure how far each individual layer moves during training. For a given layer, a high similarity (SV)CCA score before and after training indicates a small movement away from initialization, while a small similarity score indicates a high movement away from initialization.
Figure 4 shows that the lowest layer in ResNet (a large model), is significantly more similar to its initialization than in the smaller models. This figure suggests that any serious feature reuse is restricted to the lowest couple of layers, which is where similarity before/after training is clearly higher for pre-trained weights vs random initialization. Basically, larger models change much less during training, especially in the lowest layers. This is true even when they are randomly initialized.

The paper concludes by presenting a feature-independent benefit to pre-training, i.e., speed convergence. ImageNet Pre-training speed converges as shown in Fig. 5. In this figure, the paper evaluates three different initialization methods: (1) ImageNet Transfer refers to training a pre-trained network; (2) Random init refers to training a randomly initialized network; (3) Mean-Var refers to training a network initialized using the mean and standard deviation of a pre-trained network, i.e., weights are sampled from N(𝜇, 𝜎) where 𝜇 and 𝜎 are the mean and variance of a pre-trained network.
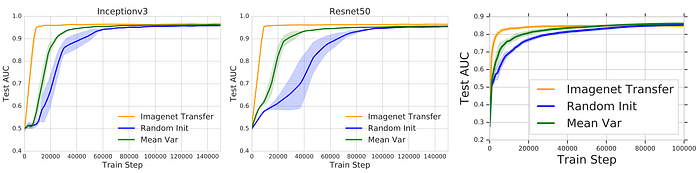
While all initialization methods achieve similar performance. ImageNet Transfer converges faster compared to Random init. The paper claims this is a feature-independent, and not feature-reuse, benefit because fast convergence speed is also achieved by Mean-Var. This evaluation refutes the idea of feature-reuse. Further experiments and evaluations are reported in the paper.
My comments:
[S] I like the detailed analysis and quality of work delivered by the paper. I highly recommend it for both the medical and computer vision community.
[W] I wish the paper emphasized the importance of lightweight (small) models. Those small models have been promoted in a single sentence by claiming that “expensive models might significantly impede mobile and on-device applications.” This single sentence is not enough. The medical sector is underfunded compared to the technological sector (FAANG). Limited funds mean limited computational power, which limits development and progress. Small competitive models, like CBR, can alleviate the development and experimentation costs.
[W] To my knowledge, the CBR models used in this paper are never released. These CBR models look competitive and the medical community could definitely benefit from these compact models.
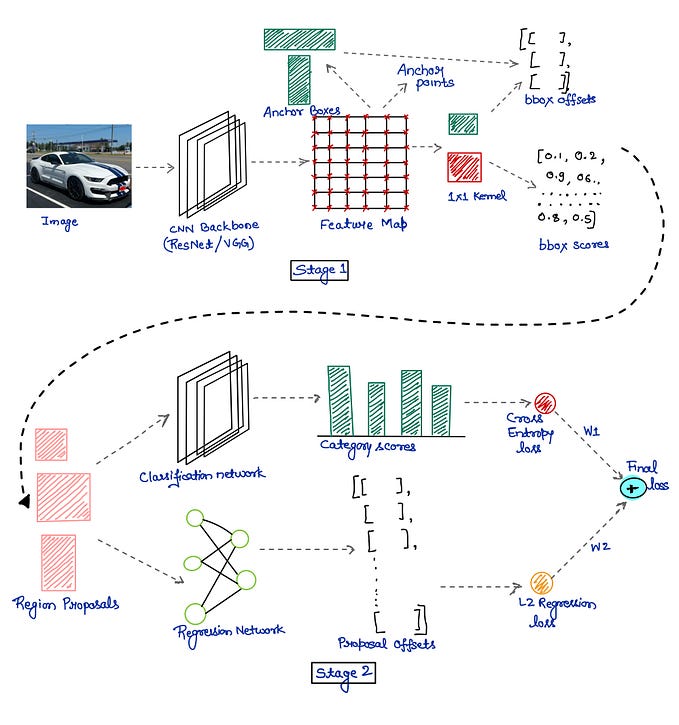
For those interested in this topic, I highly recommend [2]. He et al. [2] deliver a similar argument but for the computer vision community. Even for object detection on natural images, ImageNet pre-training is not necessary. I will conclude this article with this excerpt from [2]

Referneces
[1] Raghu, M., Zhang, C., Kleinberg, J. and Bengio, S., 2019. Transfusion: Understanding transfer learning for medical imaging. Advances in neural information processing systems
[2] He, K., Girshick, R. and Dollár, P., 2019. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision