IIRC: Incremental Implicitly-Refined Classification
While training a deep network on multiple tasks jointly is easy, training on multiple tasks sequentially is challenging. This challenge is addressed in various literature: Lifelong Learning, Incremental Learning, Continual Learning, and Never-Ending Learning. Within these forms, the common problem is catastrophic forgetting, i.e., the network forgets older tasks. To avoid forgetting, multiple engineering approaches have been proposed. Indeed, these approaches achieve better performance but the proposed solution is rarely faithful to the problem of Lifelong/Continual learning. For instance, some approaches assume that previous tasks’ outputs must remain unchanged. This assumption violates the problem of Lifelong Learning; our representations — for older concepts/tasks — evolve and develop as we learn more and more tasks.
That’s why this CVPR2021 paper [1] is interesting. The paper does not propose a new solution to catastrophic forgetting but introduces a new benchmark to study and evaluate Incremental/Continual learning. The proposed benchmark is called Incremental Implicitly-Refined Classification (IIRC). In IIRC, our representations change as we learn more and more tasks. They evolve from a coarse-grained representation to a fine-grained representation as shown in Fig. 1.

The paper raises interesting questions such as: If a network is trained on a coarse-grained label (e.g., “bear”) in an initial task and then trained on a fine-grained label (e.g., “polar bear”), what kind of associations will the network learn and what associations will it forget? Will the network generalize and label the image of a polar bear as both “bear” and “polar bear”? Will the network catastrophically forget the concept of “bear”? Will the network infer the spurious correlation: “all bears are polar bears”? What happens if the network sees different labels — of a different granularity — for the same sample? Does the network remember the latest label or the oldest label or does it remember all the labels?
These are interesting questions that go beyond the naive objective of maintaining high accuracy on older tasks. These questions revise the traditional sequential-tasks setup, i.e., an old task/concept is learned once and never revised. In contrast, the proposed IIRC benchmark allows a single image to be seen multiple times with different labels, i.e., different granularity. Then, the network is evaluated on all granularities as shown in Fig. 2.

The IIRC benchmark is a bit complex because an image can have multiple labels — coarse and grained (e.g., dog and whippet). Accordingly, training and evaluation are not straightforward. IIRC has two information setups: incomplete and complete. In the incomplete-setup, the network sees a single label per image, even if the image has multiple labels. For instance, while a whippet is also a dog, a network is trained with the whippet label only during an incomplete setup as shown in the second task (blue) in Fig. 2. Furthermore, while the network is trained on a single label per image, it is evaluated on all image labels per image. So, after an incomplete training setup, the trained network is evaluated using all labels per image — both dog and whippet!
In contrast to the incomplete-setup, the complete-setup is straightforward. The network is trained using all labels per image and evaluated on all labels per image. Of course, this setup defies the goal of incremental learning. Thus, this complete-setup is only proposed as an upper bound baseline.
Even after defining both incomplete and complete setups, there is still one pending decision: During training on a new task, are older tasks’ images (data) accessible? This question brings the concept of a replay buffer. This buffer stores a subset, or all, data from older tasks. Then, this buffer is replayed when training on a new task to mitigate older tasks’ forgetting. The buffer size is a hyperparameter that ranges from zero to infinity; zero means no replay buffer used, while infinity means all previous tasks’ images are accessible. It is important to note that the replay buffer is orthogonal to the incomplete/complete training setups. While the incomplete/complete setups specify the training labels (outputs) for a new task, the replay buffer specifies whether images (inputs) from previous tasks are accessible or not. Note that the former is about labels, while the latter is about input images.
After defining these technical details, it’s time for quantitative evaluations. The paper delivers a ton of experiments. This article will focus on a single experiment with a profound finding. It is assumed/conceived that incremental/continual learning is solvable if we have an infinite replay-buffer. Concretely, if we had access to all inputs from previous tasks, we would avoid catastrophic forgetting. The paper finds that this is not true. Fig. 3 compares multiple baselines for incremental/continual learning. This article will focus on two baselines: incremental joint (pink) and Experience Replay (ER) infinite (yellow). Both baselines have access to all data while training across tasks, i.e., previous tasks data (inputs) are accessible. The only difference is the labels associated with these inputs. Incremental joint leverages the complete-setup, where all labels per image are available; i.e., both coarse-grained labels from previous tasks and fine-grained labels from current tasks are used during training. In contrast, ER-infinite leverages the incomplete-setup, where a single label per image is available, i.e., either the coarse-grained label from a previous task or the fine-grained label from the current task is used during training.

Both increment-joint and ER-infinite train using the same input images, but with different training labels. As shown in Fig. 3, there is a significant discrepancy between the performance of the ER-infinite and the incremental joint baselines. Thus, storing data from previous tasks is not enough to tackle incremental/continual learning even if we assumed infinite-buffer. In the paper words, “This result tells us that dealing with the memory constraint is not sufficient by itself for a model to be able to perform well in the IIRC setup.”
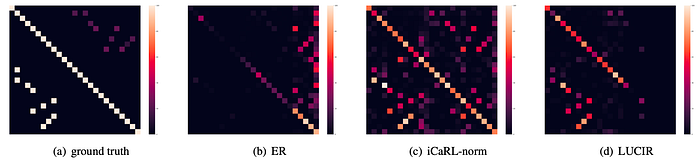
After evaluating various baselines, the paper evaluates the association between old and new labels (concepts). Concretely, the paper inspects the confusion matrices after training on ten tasks from the CIFAR dataset. Fig. 4 compares the groundtruth confusion matrix with three incremental learning baselines (ER, iCaRL, and LUCIR). The paper states that “The iCaRL-norm model, as shown in Fig. 4(c), performs relatively well in terms of associating superclasses to subclasses. E.g., whales are always correctly labeled as aquatic mammals, and pickup trucks are correctly labeled as vehicles 94% of the time. However, these models learn some spurious associations as well. For instance, ‘television’ is often mislabeled as ‘food containers’.”
My Comments:
- The paper introduction is easy to read and the problem is well motivated. Given the complexity of IIRC, the authors released the IIRC benchmark as a python package.
- To study association between concepts (labels), the paper manually inspects the groundtruth confusion matrices against the learned confusion matrix. Yet, I wish the paper proposed a metric to quantify the association between the learned concepts.
- IIRC casts incremental/continual learning as a multi-label classification problem. The total number of classes is known and fixed; a Sigmoid is applied on class logits, i.e., instead of using Softmax. Automatically, this raises the question of how to add new classes? This is a legitimate question for incremental/continual learning where knowledge adds up. I think IIRC should have learned a feature embedding instead of class logits. With embedding, adding new classes is straightforward — since the network’s output remains the same. Furthermore, it is natural to cluster features (classes) in the feature embedding. This serves as a quantitative metric to measure the association between different concepts.
References
[1] Abdelsalam, M., Faramarzi, M., Sodhani, S. and Chandar, S., 2021. IIRC: Incremental Implicitly-Refined Classification. CVPR2021
