High Resolution Images and Efficient Transformers
ResNet and ViT models achieve competitive performance, but they are not the best. For instance, DenseNets achieve superior performance to ResNets. Yet, DenseNets are less popular than ResNet. So why are ResNets and ViT models so popular in literature? One should not attribute their success to a single factor. Yet, there is a common factor between both architectures. Both architectures are easy to implement and understand. They are both simple.
While this simplicity has been vital for their success, ResNets and ViTs are designed for natural images with small resolutions (e.g., 224x224). Both architectures struggle with high-resolution inputs (e.g., 2500x2500). On one hand, a ViT model struggles with high-resolution images because these images translate into a large number of tokens, i.e., a large sequence length. These large sequences are computationally expensive for the self-attention layers due to their quadratic complexity. On the other hand, a ResNet — or a pure CNN — struggles with high-resolution images because its effective receptive field is not large enough to cover a high-resolution image. Concretely, a deeper ResNet is needed to effectively process a high-resolution image. Unfortunately, a deeper ResNet means more layers and more computations which are costly for high-resolution inputs.
Therefore, a simple and computationally friendly architecture is needed for high-resolution inputs which are common in medical imaging and satellite image applications. This paper [1] proposes a novel architecture called High resolution Convolutional Transformer (HCT). This simple architecture combines both the efficiency of convolutional layers and the global attention of transformers. HCT efficiently processes high-resolution images up to 3328x2560 pixels, as shown in Fig. 1.

The efficiency of HCT manifests during training as we want to fit a large batch-size on a single GPU. A large batch-size is favorable for two reasons: (1) it reduces the training time (wall-clock) by increasing our GPU utilization; (2) it boosts performance by stabilizing the running statistics of normalization layers (e.g., BatchNorm2d). HCT leverages a batch-size of bz=32 high-resolution images (3328x2560) with full-precision (float32) on a single A6000 GPU. Fortunately, all these advantages come with a simple architectural design.
HCT follows a ResNet-style as shown in Fig. 2. HCT has a 7x7 convolutional stem followed by five stages. This ResNet-style has multiple advantages: (1) It supports different input resolutions. Thus, HCT can switch between different input resolutions without any architectural changes; (2) The different stages produce a feature-pyramid with different resolutions. Thus, HCT supports both classification and detection tasks.

In a pure CNN, each stage contains pure convolutional blocks (e.g., BasicBlock and Bottleneck). Similarly, HCT uses pure convolutional blocks but only at early stages. Different from pure CNN, HCT uses transformers at later stages. These transformers equip HCT with a global receptive field which reduces the number of layers (depth) required to process high-resolution images.
To integrate an efficient transformer within a ResNet Stage, HCT proposes an attention-convolutional (AC) block as shown in Fig. 3. The AC block combines the global receptive field of transformers with the efficiency of convolutional layers. The AC block consumes and produces spatial feature maps. Thus, it integrates seamlessly into various computer vision architectures. HCT leverages Performers to perform the attention operation. A Performer is an efficient transformer with a linear-complexity self-attention layer.

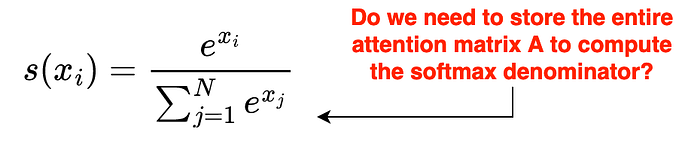
Using a simple `reshape` operation, the self-attention layer is applied to all spatial locations within a feature map as shown in Fig. 4. This global attention has multiple advantages: (1) It reduces the number of hyperparameters compared to block-wise approaches (e.g., local attention), (2) it makes no assumption about the number of tokens (feature maps’ size). So this allows different input resolutions — as in CNNs — without bells and whistles.

These simple design decisions make HCT’s implementation trivial. Fig. 5 shows the feedforward of the attention-convolutional (AC) block. It follows a BasicBlock style, which is used in standard ResNets (e.g., ResNet 18). The only difference is that it replaces one convolutional operation with a global self-attention operation wrapped within a `reshape` operation.

Besides the qualitative evaluation in Fig. 1, HCT brings a significant performance boost as shown in Tab. 1. HCT boosts performance with a smaller number of parameters and GFlops.

To emphasize the importance of processing medical images at their high-resolution, Fig. 6 presents the performance of multiple architectures with full (3328x2560) and half (1664x1280) resolutions. By using medical images at full-resolution, light-weight architectures — such as HCT — boost performance significantly.

Last thoughts
- For those interested in understanding and evaluating the effective receptive field, I wrote this article to explain this topic.
- The code for HCT has been released publicly at Github.
- HCT is a small model with 1.7 million parameters. Accordingly, HCT is a good starting point in a fully-supervised setting with small and medium datasets. Yet, HCT needs scaling (e.g., more dimensions and layers) to cope with huge datasets that are typically used in un/self-supervised learning methods.
- HCT needs scaling to cope with un/self-supervised approaches. I want to emphasize this point by referring to another paper [2] that claims that small models move further from their initialization during training compared to large (overparameterized) models as shown in Fig. 7. This means that light-weight models are inferior for self-supervised learning. These light-weight models will “forget” what they learned during self-supervised learning. This aligns with recent empirical evidence where large (scaled-)architectures are required to cope with bigger unlabeled datasets.

References
[1] Taha, A., Truong Vu, Y.N., Mombourquette, B., Matthews, T.P., Su, J. and Singh, S., 2022, September. Deep is a Luxury We Don’t Have. MICCAI 2022
[2] Raghu, M., Zhang, C., Kleinberg, J. and Bengio, S., 2019. Transfusion: Understanding transfer learning for medical imaging. NeurIPS.