PinnedAhmed TahaL2-CAF: A Neural Network DebuggerEvery software engineer has used a debugger to debug his code. Yet, a neural network debugger… That’s news! This paper [1] proposes a…5 min read·May 24, 2021----
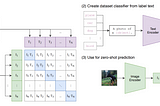
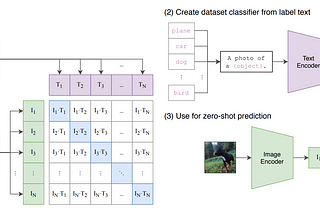
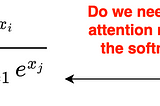
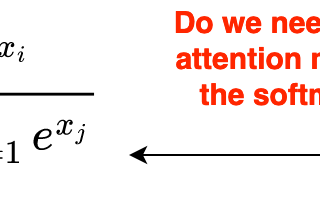
Ahmed TahaSigmoid Loss for Language Image Pre-TrainingContrastive Language Image Pre-training (CLIP) has gained significant momentum after OpenAI’s CLIP paper [2]. CLIP uses image-text pairs to…9 min read·Mar 18, 2024----
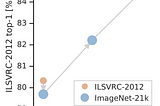
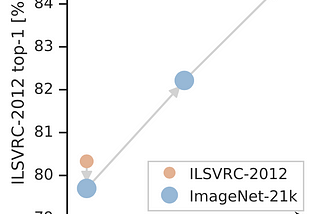
Ahmed TahaBig Transfer (BiT): General Visual Representation LearningPre-trained representations bring two benefits during fine-tuning: (1) improved sample efficiency, and (2) simplified hyperparameter…5 min read·Jul 3, 2023----
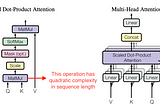
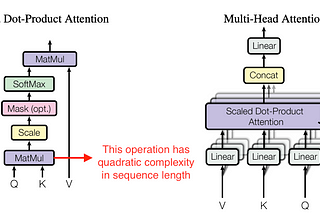
Ahmed TahaFlashAttention: Fast and Memory-Efficient Exact Attention with IO-AwarenessStandard attention suffers quadratic complexity in terms of the sequence length (number of tokens). To reduce complexity, efficient…8 min read·Jun 5, 2023--3--3
Ahmed TahaHigh Resolution Images and Efficient TransformersResNet and ViT models achieve competitive performance, but they are not the best. For instance, DenseNets achieve superior performance to…5 min read·May 9, 2023----
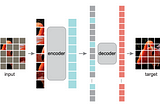
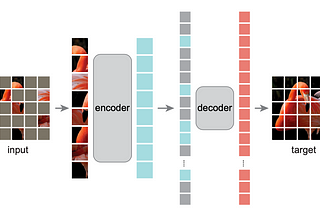
Ahmed TahaMasked Autoencoders Are Scalable Vision LearnersAnnotated data is a vital pillar of deep learning. Yet, annotated data is rare in certain applications (e.g., medical and robotics). To…7 min read·Mar 27, 2023----
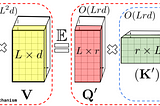
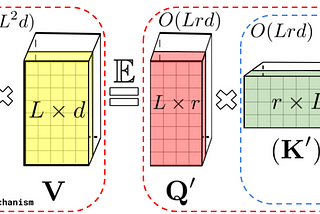
Ahmed TahaRethinking Attention with Performers — Part II & FinalThis article’s objective is to summarize the Performers [1] paper. The article highlights key details and documents some personal comments…7 min read·Feb 14, 2023----
Ahmed TahaRethinking Attention with Performers — Part IThis article’s objective is to present a high-level hand-wavy understanding of how Performers [1] work.7 min read·Oct 11, 2022--1--1
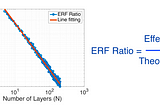
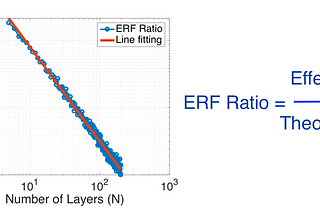
Ahmed TahaUnderstanding the Effective Receptive Field in Deep Convolutional Neural NetworksIn deep networks, a receptive field — or field of view — is the region in the input space that affects a particular layer’s feature as…5 min read·May 16, 2022----
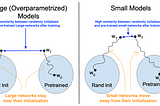
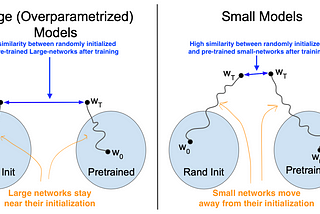
Ahmed TahaUnderstanding Transfer Learning for Medical ImagingTransfer learning (a.k.a. ImageNet pre-training) is a common practice in deep learning where a pre-trained network is fine-tuned on a new…6 min read·Apr 4, 2022--1--1